Abstract
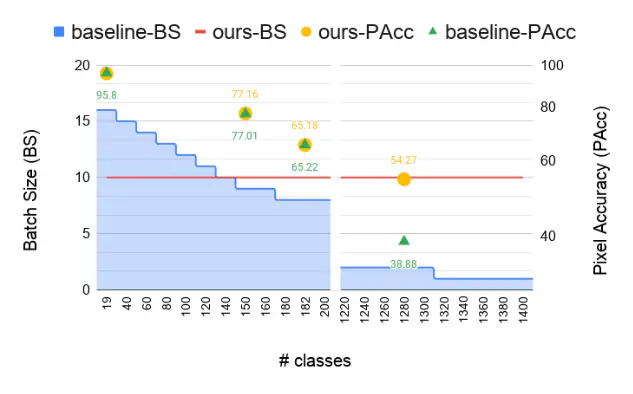
The state-of-the-art object detection and image classification methods can perform impressively on more than 9k and 10k classes, respectively. In contrast, the number of classes in semantic segmentation datasets is relatively limited. This is not surprising when the restrictions caused by the lack of labeled data and high computation demand for segmentation are considered. In this paper, we propose a novel training methodology to train and scale the existing semantic segmentation models for a large number of semantic classes without increasing the memory overhead. In our embedding-based scalable segmentation approach, we reduce the space complexity of the segmentation model’s output from O(C) to O(1), propose an approximation method for ground-truth class probability, and use it to compute cross-entropy loss. The proposed approach is general and can be adopted by any state-of-the-art segmentation model to gracefully scale it for any number of semantic classes with only one GPU. Our approach achieves similar, and in some cases, even better mIoU for Cityscapes, Pascal VOC, ADE20k, COCO-Stuff10k datasets when adopted to DeeplabV3+ model with different backbones. We demonstrate a clear benefit of our approach on a dataset with 1284 classes, bootstrapped from LVIS and COCO annotations, with three times better mIoU than the DeeplabV3+ model.