Abstract
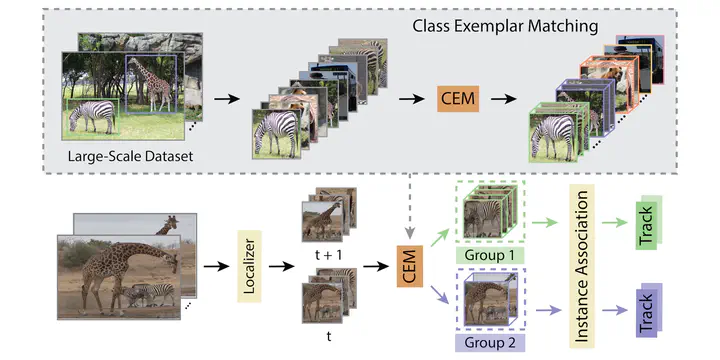
Current multi-category Multiple Object Tracking (MOT) metrics use class labels to group tracking results for per-class evaluation. Similarly, MOT methods typically only associate objects with the same class predictions. These two prevalent strategies in MOT implicitly assume that the classification performance is near-perfect. However, this is far from the case in recent large-scale MOT datasets, which contain large numbers of classes with many rare or semantically similar categories. Therefore, the resulting inaccurate classification leads to sub-optimal tracking and inadequate benchmarking of trackers. We address these issues by disentangling classification from tracking. We introduce a new metric, Track Every Thing Accuracy (TETA), breaking tracking measurement into three sub-factors: localization, association, and classification, allowing comprehensive benchmarking of tracking performance even under inaccurate classification. TETA also deals with the challenging incomplete annotation problem in large-scale tracking datasets. We further introduce a Track Every Thing tracker (TETer), that performs association using Class Exemplar Matching (CEM). Our experiments show that TETA evaluates trackers more comprehensively, and TETer achieves significant improvements on the challenging large-scale datasets BDD100K and TAO compared to the state-of-the-art.